Part 3-2: Memory & Addressing
The previous article was getting too long. So I decided to make it a 2 part. This is the second half where we are going to talk about memories and addressing.
Stack and Heap
It is very important to notice what is reserved and what is not before, during and after a procedure.
Reserved: sp, fp, ra, and anything on the stack above sp
Not reserved: temporaries (t0–t6), arguments (a0–a7), and anything on the stack below sp
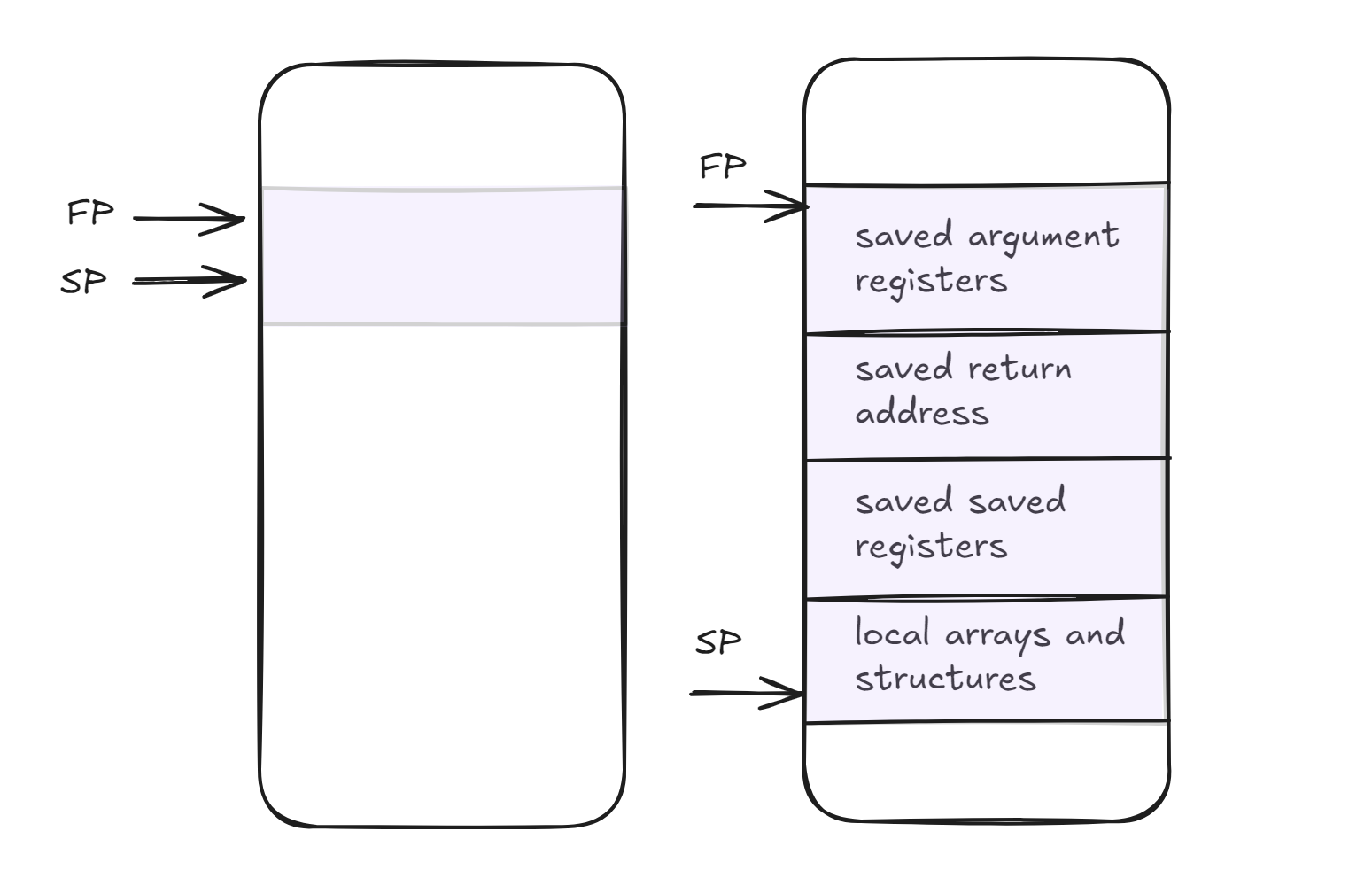
We mention fp here. Frame pointers are stored in x8 and it points to the first doubleword of the frame. fp and sp initially start at the same address but during the procedure call sp changes while fp stays the same. This gives us a stable point to address from for local-memory references. I have provided a diagram that shows how it changes from before/after the procedure call to during the procedure. In RISC V, compiler only uses frame pointers in procedures that change the stack pointer during the execution.
 There are also different place where variables are preserved. They are in the “static data” portion of the memory. You can also look at the diagram below. In C, any variable declared as static goes there. If static keyword is not used, it is considered an automatic variable. Automatic variables are the variables we have been using - those that are local to the procedure.
There are also different place where variables are preserved. They are in the “static data” portion of the memory. You can also look at the diagram below. In C, any variable declared as static goes there. If static keyword is not used, it is considered an automatic variable. Automatic variables are the variables we have been using - those that are local to the procedure.
To access the static variables, we have a special register global pointer (gp) stored in x3.
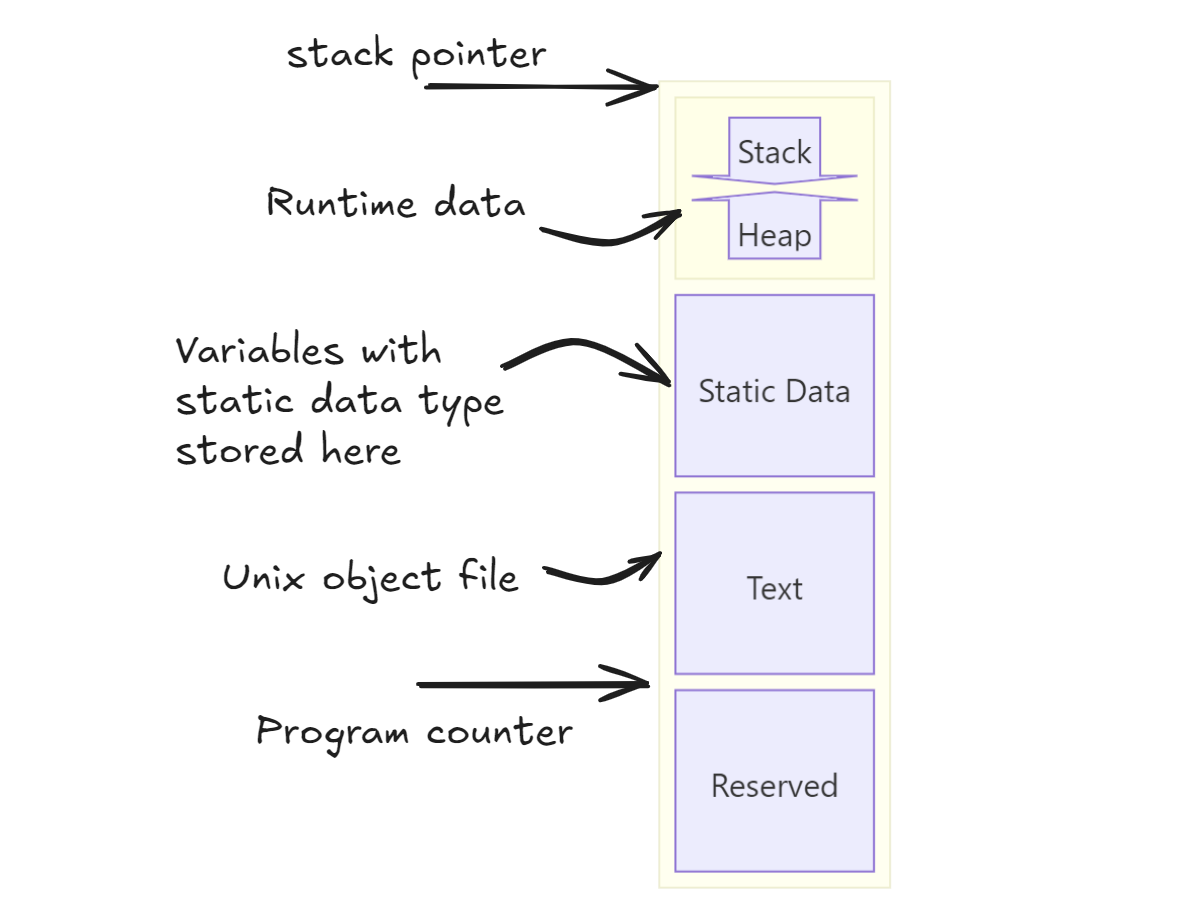 In the runtime data, there is another memory space called heap. This is where we store another type of data that is called “dynamic data”. Dynamic data is basically data structures that change their size during the course of an execution of a program. Think linked lists, or graphs. In C, we use malloc() and free() to allocate and free memory with each operation giving us pointer afterwards. This causes a lot of trouble for the programmer because if you forget to free the space, you’ll get “memory leak”, free it up too early and you’re left with “dangling pointers”. But Java uses automatic memory allocation and garbage collector to avoid such bugs.
In the runtime data, there is another memory space called heap. This is where we store another type of data that is called “dynamic data”. Dynamic data is basically data structures that change their size during the course of an execution of a program. Think linked lists, or graphs. In C, we use malloc() and free() to allocate and free memory with each operation giving us pointer afterwards. This causes a lot of trouble for the programmer because if you forget to free the space, you’ll get “memory leak”, free it up too early and you’re left with “dangling pointers”. But Java uses automatic memory allocation and garbage collector to avoid such bugs.
Characters and Strings
Computers were initially developed for calculations but as soon as it was commercialized, it became apparent, computers needed to process text. So we developed a way to store text. One way is to use ASCII, each character is given their own unique code and stored in 8 bits. You can do the math and see we have $2^8$ unique characters in ASCII.
But before we go into that, let’s talk hardware. So far, we only had ld/sd or lw/sw, these load/store doublewords or words, but to get a single byte from memory we would need specific instructions.
The instructions are lbu for loading and sb for storing. They choose the rightmost 8 bits as the byte to load/store. Here is a useful diagram:
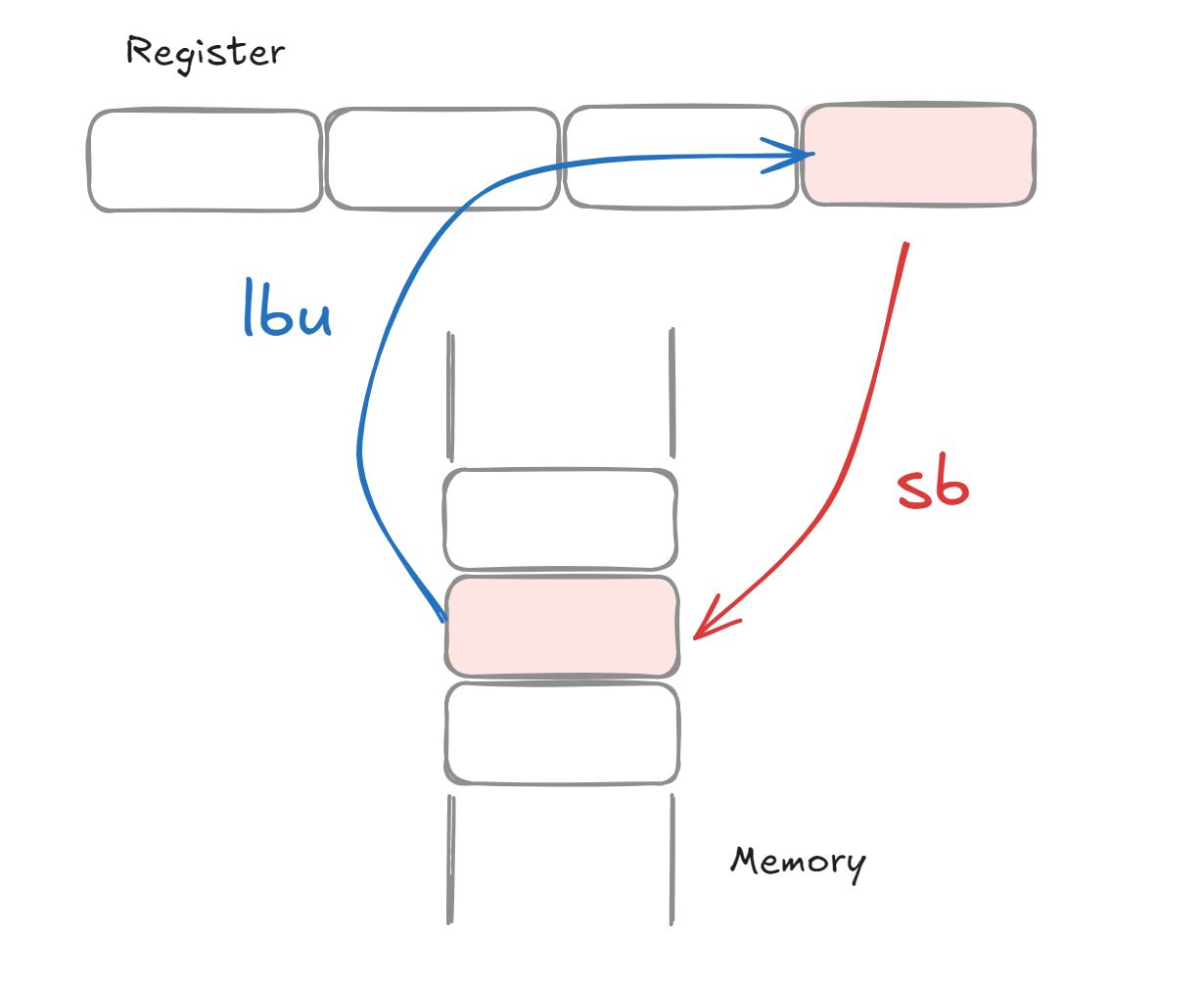 Another note on how this relates to hardware is that this is the reason why memory is byte addressed. Otherwise, if you just think about instructions, it will always be a word/doubleword, so there is no reason to do the arithmetic of
Another note on how this relates to hardware is that this is the reason why memory is byte addressed. Otherwise, if you just think about instructions, it will always be a word/doubleword, so there is no reason to do the arithmetic of pc=pc+4. We could just get away with pc=pc+1.
This is how C stores characters. You can make an array of these characters to make - a string. There are multiple ways to store a string.
- First portion of the string tells you the length of the string
- Accompanying variable has the length of the string
- At the end of the string, there is a special character
C uses the last option to store strings and Java uses option 1. Java uses 2 bytes to store a character. This is because Java uses Unicode instead of ASCII. It has more alphabets like Greek, Latin and Mongolian :D
So for Java, we need other set of instructions lhu and sh. These instructions load/store rightmost 16 bits.

Addressing for Wide Immediate and Addresses
There is an instruction called load upper immediate (lui). It loads 20 bit constant into bits 31 through 12, fills the left side (63-31) with copies of bit 31 and right bits (11-0) with 0s. lui uses a new format called U-type that can accommodate large constants.

Branching example
